
Sketchnotes from TWiML&AI: Adversarial Attacks Against Reinforcement Learning Agents with Ian Goodfellow & Sandy Huang
These are my sketchnotes for Sam Charrington’s podcast This Week in Machine Learning and AI about Adversarial Attacks Against Reinforcement Learning Agents with Ian Goodfellow & Sandy Huang:
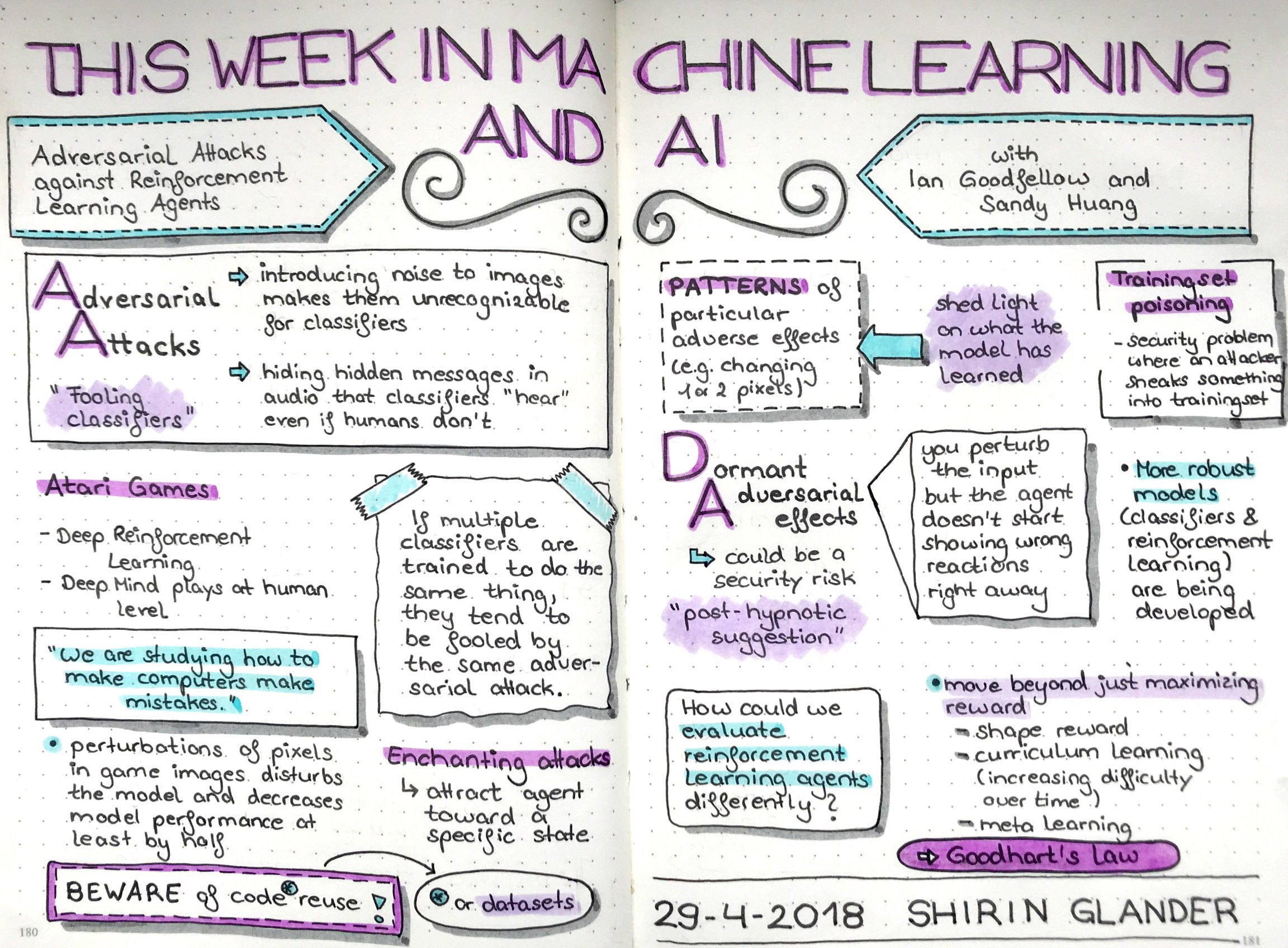
Sketchnotes from TWiMLAI talk: Adversarial Attacks Against Reinforcement Learning Agents with Ian Goodfellow & Sandy Huang
You can listen to the podcast here.
In this episode, I’m joined by Ian Goodfellow, Staff Research Scientist at Google Brain and Sandy Huang, Phd Student in the EECS department at UC Berkeley, to discuss their work on the paper Adversarial Attacks on Neural Network Policies. If you’re a regular listener here you’ve probably heard of adversarial attacks, and have seen examples of deep learning based object detectors that can be fooled into thinking that, for example, a giraffe is actually a school bus, by injecting some imperceptible noise into the image. Well, Sandy and Ian’s paper sits at the intersection of adversarial attacks and reinforcement learning, another area we’ve discussed quite a bit on the podcast. In their paper, they describe how adversarial attacks can also be effective at targeting neural network policies in reinforcement learning. Sandy gives us an overview of the paper, including how changing a single pixel value can throw off performance of a model trained to play Atari games. We also cover a lot of interesting topics relating to adversarial attacks and RL individually, and some related areas such as hierarchical reward functions and transfer learning. This was a great conversation that I’m really excited to bring to you! https://twimlai.com/twiml-talk-119-adversarial-attacks-reinforcement-learning-agents-ian-goodfellow-sandy-huang/
