
Slides from my m-cubed talk about Explaining complex machine learning models with LIME
The last two days, I was in London for the M-cubed conference.
Here are the slides from my talk about Explaining complex machine learning models with LIME:
Traditional machine learning workflows focus heavily on model training and optimization; the best model is usually chosen via performance measures like accuracy or error and we tend to assume that a model is good enough for deployment if it passes certain thresholds of these performance criteria. Why a model makes the predictions it makes, however, is generally neglected. But being able to understand and interpret such models can be immensely important for improving model quality, increasing trust and transparency and for reducing bias. Because complex machine learning models are essentially black boxes and too complicated to understand, we need to use approximations.
I also took sketchnotes from the two keynote lectures:

HUMAN MINDS AND MACHINE INTELLIGENCE – WHO’S THE MASTER? by Dr Joanna Bryson
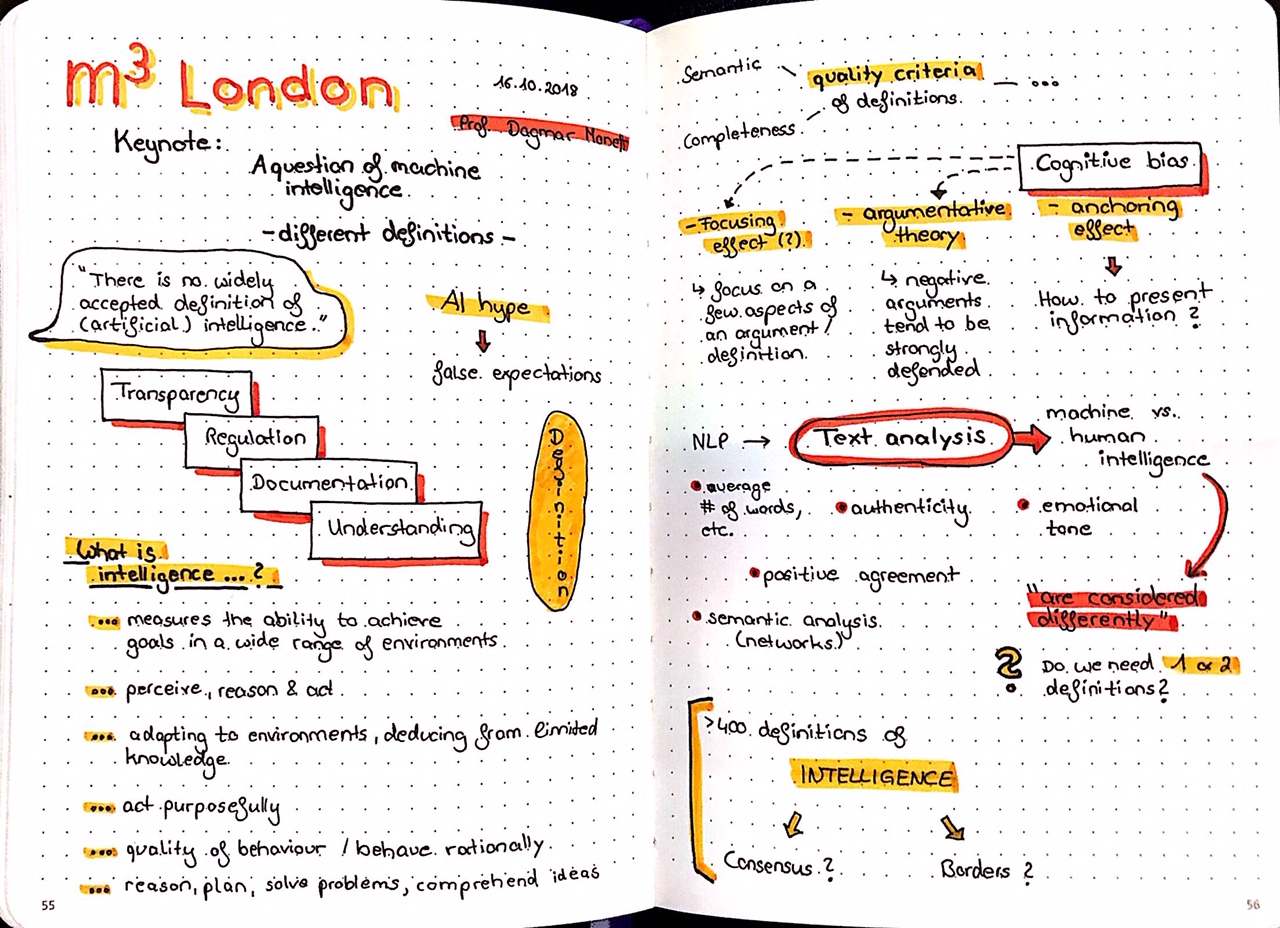
A QUESTION OF MACHINE INTELLIGENCE – STRONG ARGUMENTS IN SUPPORT OF AND AGAINST DIFFERENT DEFINITIONS by Prof. Dagmar Monett Diaz
