
Sketchnotes from TWiML&AI: Evaluating Model Explainability Methods with Sara Hooker
These are my sketchnotes for Sam Charrington’s podcast This Week in Machine Learning and AI about Evaluating Model Explainability Methods with Sara Hooker:
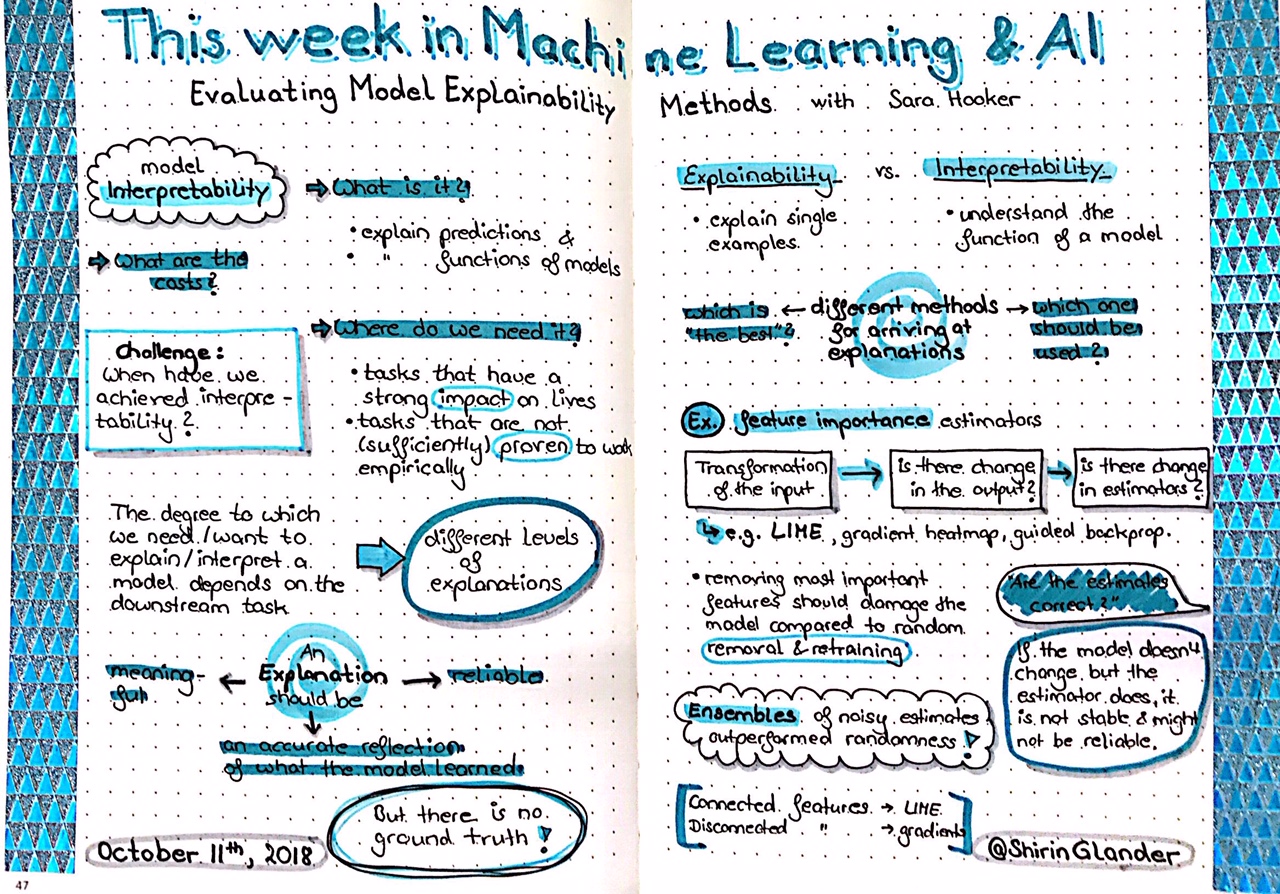
Sketchnotes from TWiMLAI talk: Evaluating Model Explainability Methods with Sara Hooker
You can listen to the podcast here.
In this, the first episode of the Deep Learning Indaba series, we’re joined by Sara Hooker, AI Resident at Google Brain. I had the pleasure of speaking with Sara in the run-up to the Indaba about her work on interpretability in deep neural networks. We discuss what interpretability means and when it’s important, and explore some nuances like the distinction between interpreting model decisions vs model function. We also dig into her paper Evaluating Feature Importance Estimates and look at the relationship between this work and interpretability approaches like LIME. We also talk a bit about Google, in particular, the relationship between Brain and the rest of the Google AI landscape and the significance of the recently announced Google AI Lab in Accra, Ghana, being led by friend of the show Moustapha Cisse. And, of course, we chat a bit about the Indaba as well. https://twimlai.com/twiml-talk-189-evaluating-model-explainability-methods-with-sara-hooker/
