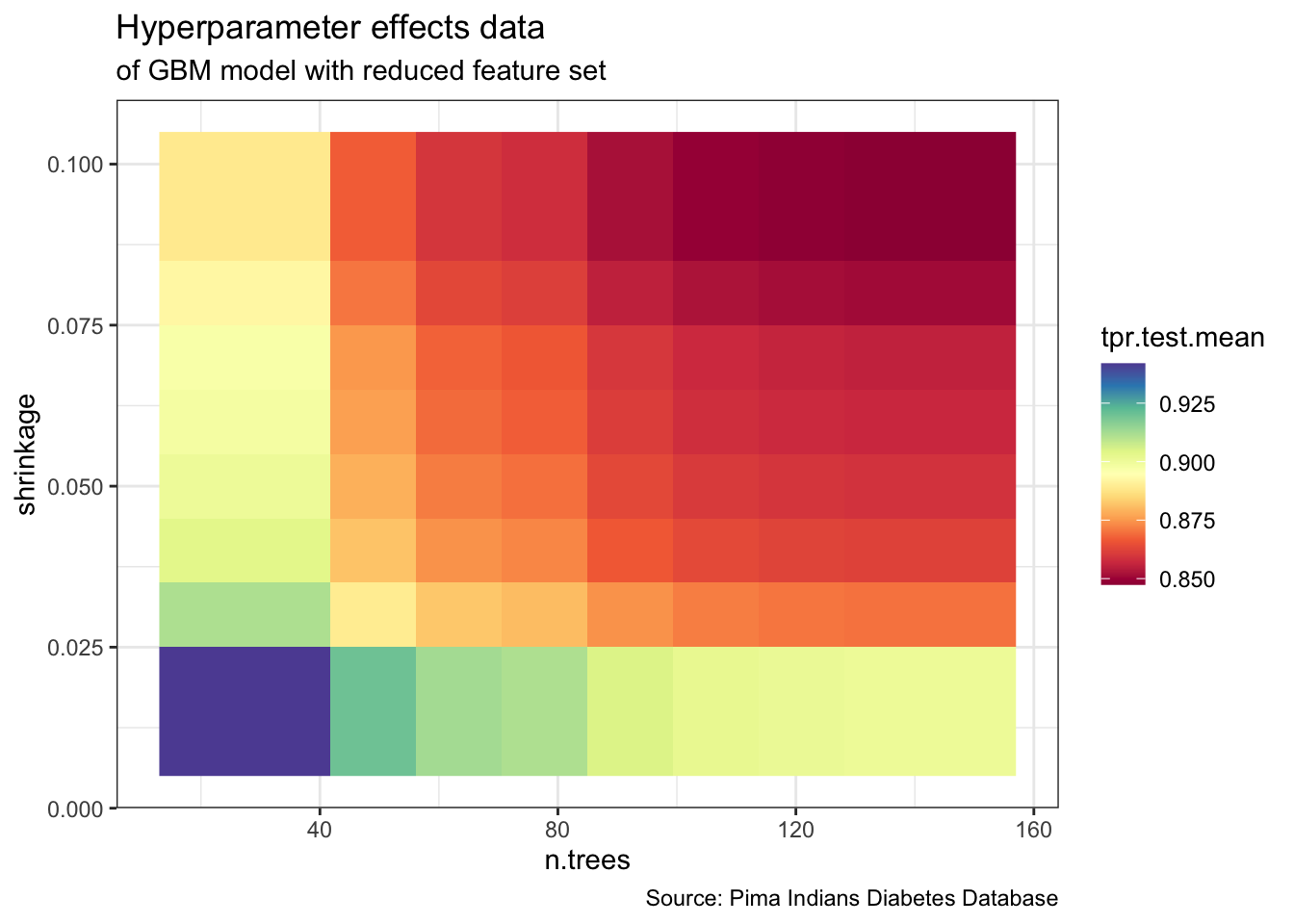
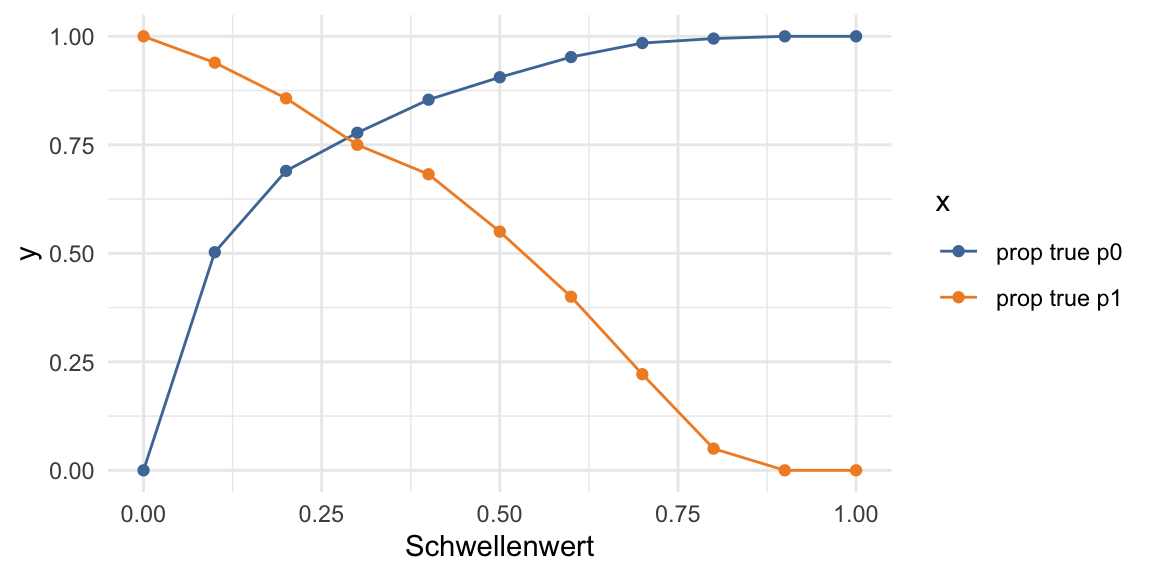
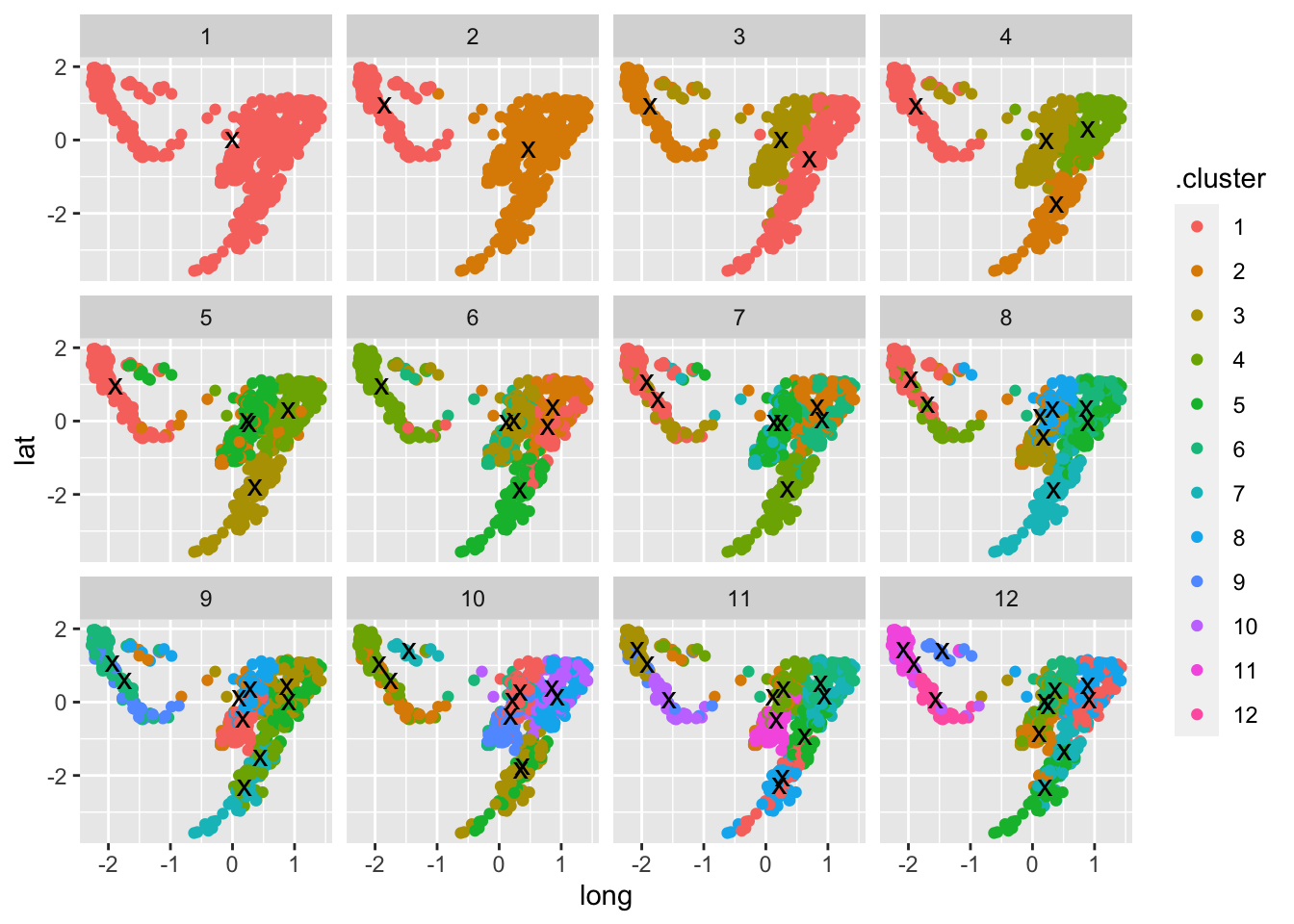
This is code accompanying an article about Data Storytelling in the German IT magazine iX 1/2022. The figures in this article were created as follows.
Note: Because the data is partly from a German source, the data description is in German as well.
iX 1/2022
library(readr) library(tidyverse) library(stringr) library(lubridate) Set colorblind-friendly palette cbp2 <- c("#000000", "#E69F00", "#56B4E9", "#009E73", "#999999", "#0072B2", "#D55E00", "#CC79A7") ggplot <- function(...) ggplot2::ggplot(...) + scale_color_manual(values = cbp2) + scale_fill_manual(values = cbp2) + # note: needs to be overridden when using continuous color scales theme_bw() library(plotrix) sliceValues <- rep(10, 8) # each slice value=10 for proportionate slices ( p <- pie3D(sliceValues, explode=0, theta = 1.
Continue reading