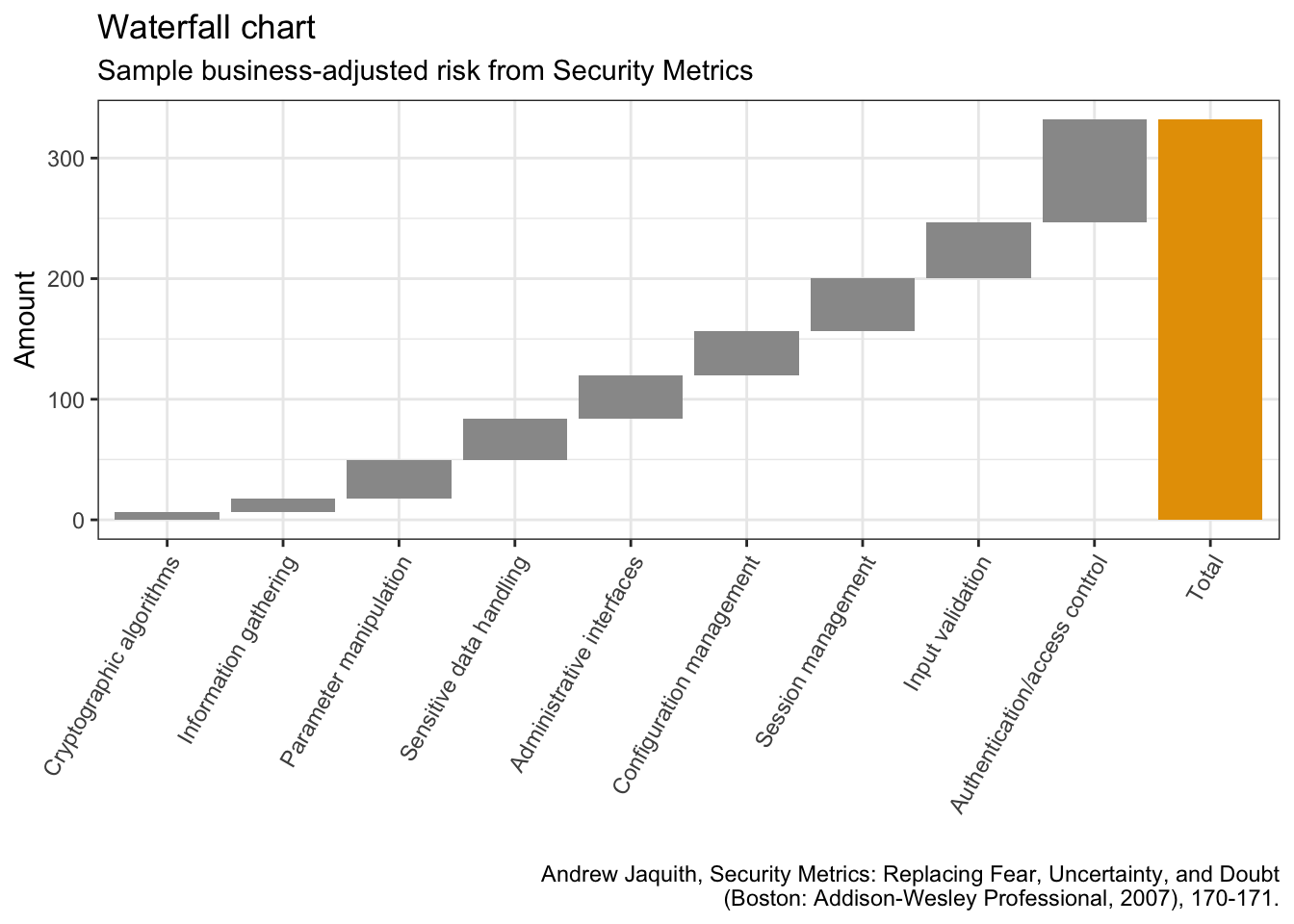
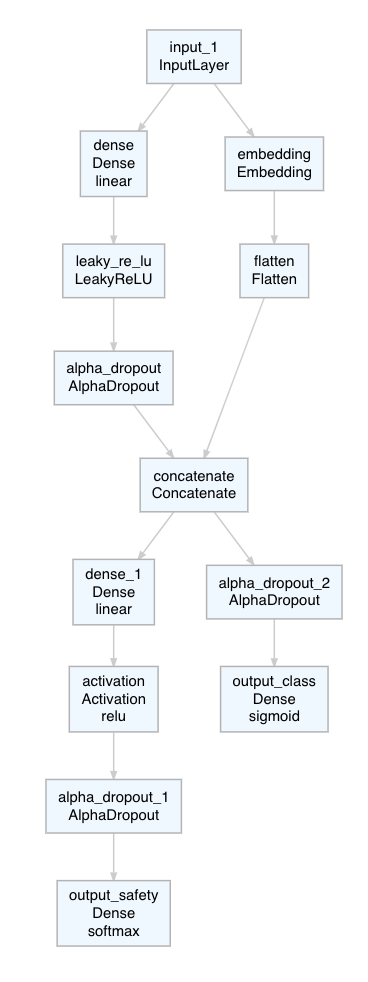
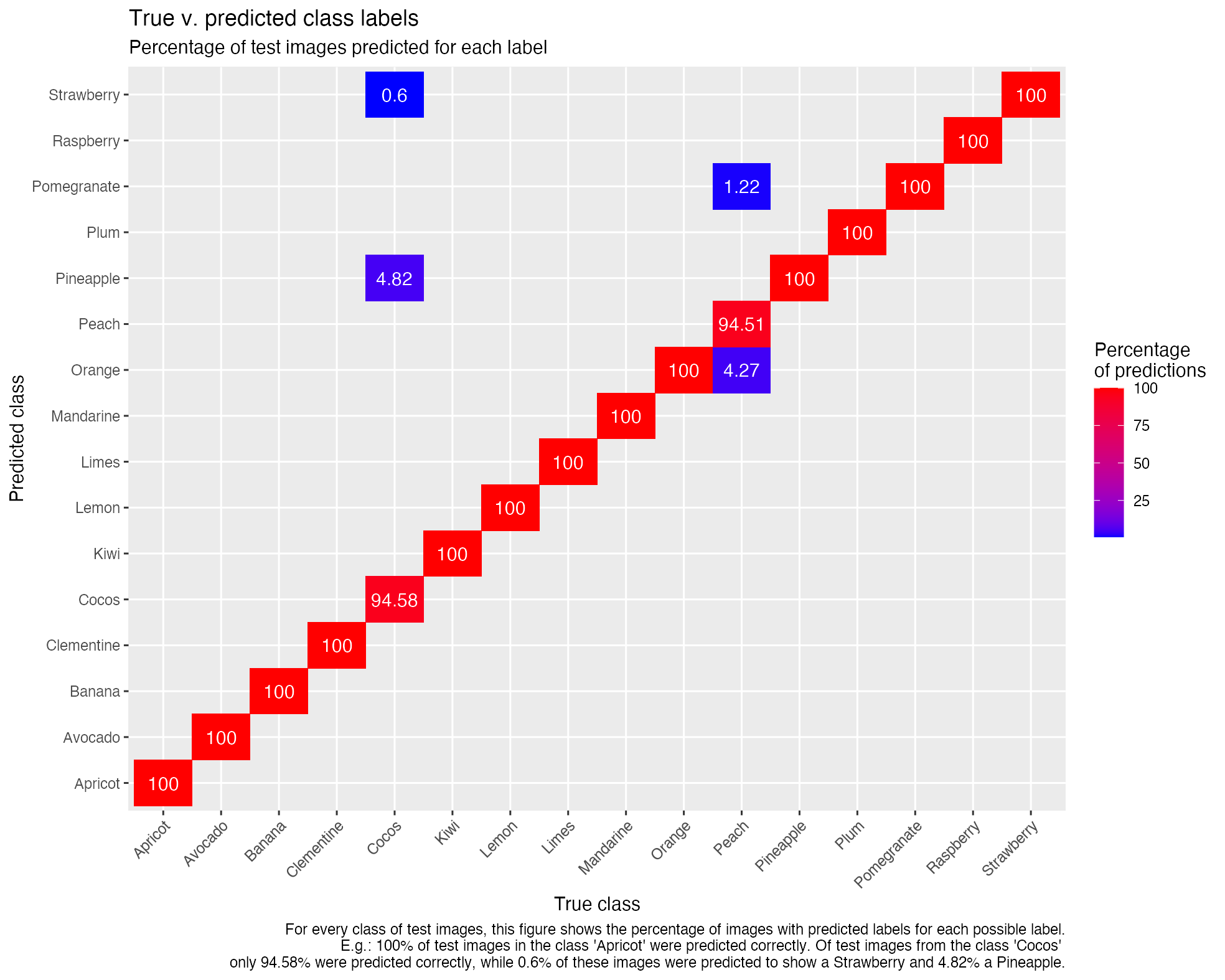
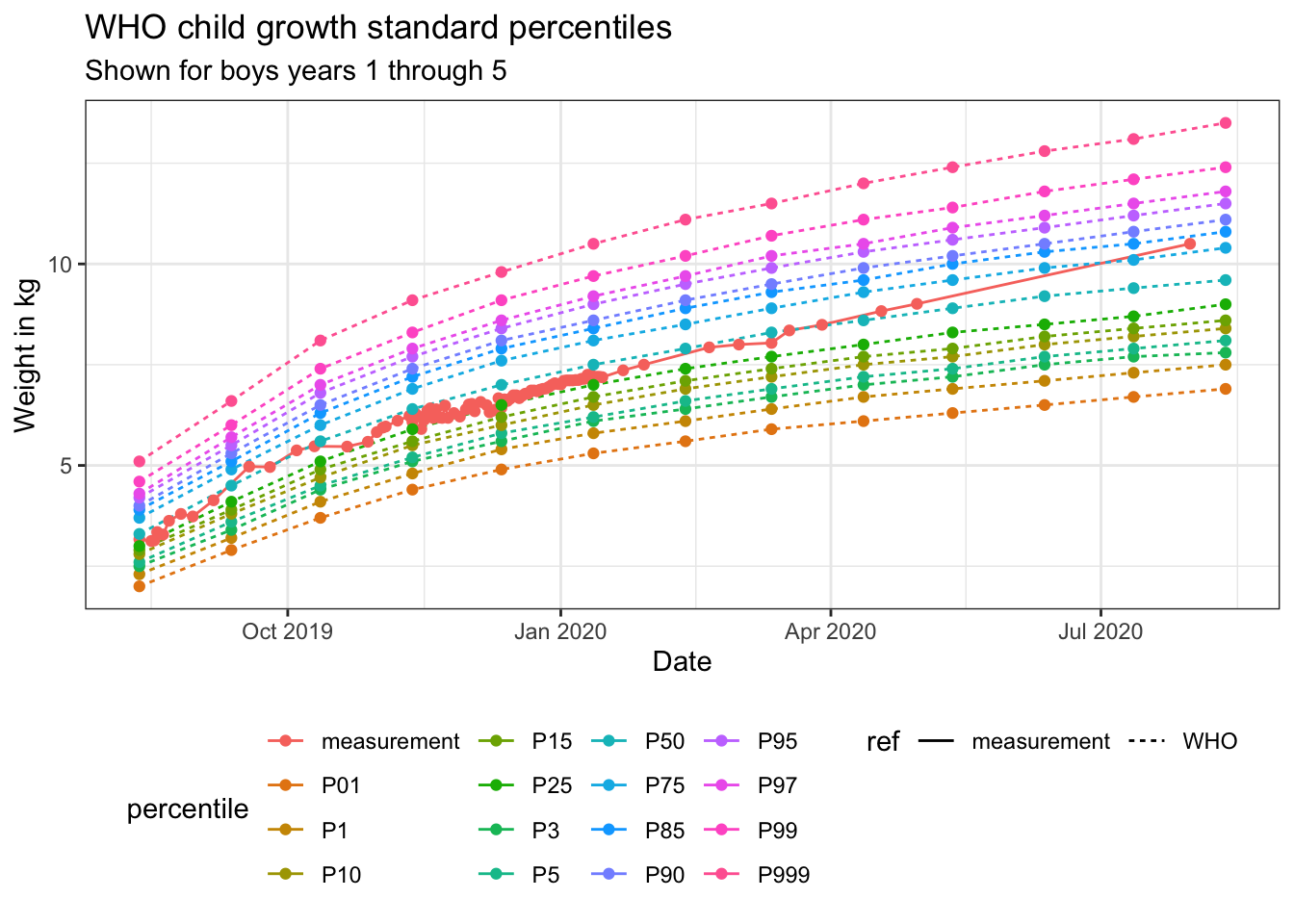
Below you’ll find the complete code used to create the ggplot2 graphs in my talk The Good, the Bad and the Ugly: how (not) to visualize data at this year’s data2day conference. You can find the German slides here:
You can also find a German blog article accompanying my talk on codecentric’s blog.
If you have questions or would like to talk about this article (or something else data-related), you can now book 15-minute timeslots with me (it’s free - one slot available per weekday):